import os
import picamera
import serial
import time
import board
import adafruit_bmp280
import RPi.GPIO as GPIO
GPIO.setwarnings(False)
#GPIO.setmode(GPIO.BOARD)
GPIO.setup(18, GPIO.OUT, initial=GPIO.LOW)
i2c = board.I2C()
bmp = adafruit_bmp280.Adafruit_BMP280_I2C(i2c)
bmp.sea_level_pressure = 1013.25
camera = picamera.PiCamera()
camera.resolution = (1280, 720)
camera.rotation = 180
framerate = 5
camera.framerate = framerate
camera.annotate_text_size = 18
gps = "GPS Data"
gpsPort = "/dev/ttyACM0"
gpsSerial = serial.Serial(gpsPort, baudrate = 9600, timeout = 0.5)
def getPicture(annotation):
filename = "/home/pi/Pictures/" + str(time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime())) + ".jpg"
try:
camera.start_preview()
time.sleep(2.5)
camera.annotate_text = annotation
camera.capture(filename)
camera.stop_preview()
except Exception as error:
return(error)
camera.stop_preview()
return filename
def getVideo(length):
filename = "/home/pi/Videos/" + str(time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime())) + ".mp4"
try:
camera.start_recording("/home/pi/testVideo.h264")
for index in range(length):
start = time.time()
camera.annotate_text = (annotate())
end = time.time()
elapsed = start - end
if elapsed <= 1:
time.sleep(1 - elapsed)
camera.stop_recording()
except Exception as error:
return(error)
os.system("ffmpeg -r " + str(framerate) + " -i /home/pi/testVideo.h264 -vcodec copy " + filename)
os.system("del /home/pi/testVideo.h264")
return filename
def gpgga():
output = ""
emailgps = ""
try:
n = 1
while output == "" and n<50:
gps = str(gpsSerial.readline())
#print(n)
if (gps[2:8] == "$GPGGA" or gps[2:8] == "$GNGGA"):
gps = gps.split(",")
#lat long formatted for digital maps
latgps = gps[2][0:2] + ' ' + gps[2][2:]
longgps = '-'+gps[4][1:3] + ' ' + gps[4][3:]
emailgps = latgps+','+longgps
latDeg = int(gps[2][0:2])
latMin = int(gps[2][2:4])
latSec = round(float(gps[2][5:9]) * (3/500))
latNS = gps[3]
output += "Latitude: " + str(latDeg) + " deg " + str(latMin) + "'" + str(latSec) + '" ' + latNS + "\n"
longDeg = int(gps[4][0:3])
longMin = int(gps[4][3:5])
longSec = round(float(gps[4][6:10]) * (3/500))
longEW = gps[5]
output += "Longitude: " + str(longDeg) + " deg " + str(longMin) + "'" + str(longSec) + '" ' + longEW + "\n"
alt = float(gps[9])
output += "Altitude: " + str(alt) + " m" + "\n"
sat = int(gps[7])
output += "Satellites: " + str(sat)
n+=1
return [output,emailgps]
except Exception as error:
return ["",""]
def gprmc():
output = ""
try:
n = 1
while output == "" and n<50:
#print(n)
gps = str(gpsSerial.readline())
if gps[2:8] == "$GPRMC" or gps[2:8] == "$GNRMC":
gps = gps.split(",")
output = ""
speed = round(float(gps[7]) * 1852)/1000
output += "Speed: " + str(speed) + " km/h"
n+=1
return output
except Exception as error:
return("")
def gps():
try:
output = gpgga()[0] + "\n" + gprmc()
return output
except Exception as error:
return("")
def accurate_altitude():
try:
output = 'BMP280 Altitude: {} m'.format(round(bmp.altitude))
return output
except Exception as error:
return("")
def annotate():
timeNow = str(time.strftime("%a %d %b %Y %H:%M:%S", time.localtime()))
locationNow = gps()
bmpa = accurate_altitude()
annotation = timeNow + "\n" + locationNow + "\n" + bmpa
return annotation
def flyBalloon():
while True:
try:
getVideo(10) #40
GPIO.output(18, GPIO.HIGH)
getPicture("")
getPicture(annotate())
GPIO.output(18,GPIO.LOW)
except Exception as error:
return(error)
flyBalloon()
Category Archives: source code
Prim’s Algorithm Maze Generation
</div>
# Maze generator -- Randomized Prim Algorithm
## Imports
import random
import time
from colorama import init
from colorama import Fore, Back, Style
## Functions
def printMaze(maze):
for i in range(0, height):
for j in range(0, width):
if (maze[i][j] == 'u'):
print(Fore.WHITE + str(maze[i][j]), end=" ")
elif (maze[i][j] == 'c'):
print(Fore.GREEN + str(maze[i][j]), end=" ")
else:
print(Fore.RED + str(maze[i][j]), end=" ")
print('\n')
# Find number of surrounding cells
def surroundingCells(rand_wall):
s_cells = 0
if (maze[rand_wall[0]-1][rand_wall[1]] == 'c'):
s_cells += 1
if (maze[rand_wall[0]+1][rand_wall[1]] == 'c'):
s_cells += 1
if (maze[rand_wall[0]][rand_wall[1]-1] == 'c'):
s_cells +=1
if (maze[rand_wall[0]][rand_wall[1]+1] == 'c'):
s_cells += 1
return s_cells
## Main code
# Init variables
wall = 'w'
cell = 'c'
unvisited = 'u'
height = 11
width = 27
maze = []
# Initialize colorama
init(convert=True)
# Denote all cells as unvisited
for i in range(0, height):
line = []
for j in range(0, width):
line.append(unvisited)
maze.append(line)
# Randomize starting point and set it a cell
starting_height = int(random.random()*height)
starting_width = int(random.random()*width)
if (starting_height == 0):
starting_height += 1
if (starting_height == height-1):
starting_height -= 1
if (starting_width == 0):
starting_width += 1
if (starting_width == width-1):
starting_width -= 1
# Mark it as cell and add surrounding walls to the list
maze[starting_height][starting_width] = cell
walls = []
walls.append([starting_height - 1, starting_width])
walls.append([starting_height, starting_width - 1])
walls.append([starting_height, starting_width + 1])
walls.append([starting_height + 1, starting_width])
# Denote walls in maze
maze[starting_height-1][starting_width] = 'w'
maze[starting_height][starting_width - 1] = 'w'
maze[starting_height][starting_width + 1] = 'w'
maze[starting_height + 1][starting_width] = 'w'
while (walls):
# Pick a random wall
rand_wall = walls[int(random.random()*len(walls))-1]
# Check if it is a left wall
if (rand_wall[1] != 0):
if (maze[rand_wall[0]][rand_wall[1]-1] == 'u' and maze[rand_wall[0]][rand_wall[1]+1] == 'c'):
# Find the number of surrounding cells
s_cells = surroundingCells(rand_wall)
if (s_cells < 2):
# Denote the new path
maze[rand_wall[0]][rand_wall[1]] = 'c'
# Mark the new walls
# Upper cell
if (rand_wall[0] != 0):
if (maze[rand_wall[0]-1][rand_wall[1]] != 'c'):
maze[rand_wall[0]-1][rand_wall[1]] = 'w'
if ([rand_wall[0]-1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]-1, rand_wall[1]])
# Bottom cell
if (rand_wall[0] != height-1):
if (maze[rand_wall[0]+1][rand_wall[1]] != 'c'):
maze[rand_wall[0]+1][rand_wall[1]] = 'w'
if ([rand_wall[0]+1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]+1, rand_wall[1]])
# Leftmost cell
if (rand_wall[1] != 0):
if (maze[rand_wall[0]][rand_wall[1]-1] != 'c'):
maze[rand_wall[0]][rand_wall[1]-1] = 'w'
if ([rand_wall[0], rand_wall[1]-1] not in walls):
walls.append([rand_wall[0], rand_wall[1]-1])
# Delete wall
for wall in walls:
if (wall[0] == rand_wall[0] and wall[1] == rand_wall[1]):
walls.remove(wall)
continue
# Check if it is an upper wall
if (rand_wall[0] != 0):
if (maze[rand_wall[0]-1][rand_wall[1]] == 'u' and maze[rand_wall[0]+1][rand_wall[1]] == 'c'):
s_cells = surroundingCells(rand_wall)
if (s_cells < 2):
# Denote the new path
maze[rand_wall[0]][rand_wall[1]] = 'c'
# Mark the new walls
# Upper cell
if (rand_wall[0] != 0):
if (maze[rand_wall[0]-1][rand_wall[1]] != 'c'):
maze[rand_wall[0]-1][rand_wall[1]] = 'w'
if ([rand_wall[0]-1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]-1, rand_wall[1]])
# Leftmost cell
if (rand_wall[1] != 0):
if (maze[rand_wall[0]][rand_wall[1]-1] != 'c'):
maze[rand_wall[0]][rand_wall[1]-1] = 'w'
if ([rand_wall[0], rand_wall[1]-1] not in walls):
walls.append([rand_wall[0], rand_wall[1]-1])
# Rightmost cell
if (rand_wall[1] != width-1):
if (maze[rand_wall[0]][rand_wall[1]+1] != 'c'):
maze[rand_wall[0]][rand_wall[1]+1] = 'w'
if ([rand_wall[0], rand_wall[1]+1] not in walls):
walls.append([rand_wall[0], rand_wall[1]+1])
# Delete wall
for wall in walls:
if (wall[0] == rand_wall[0] and wall[1] == rand_wall[1]):
walls.remove(wall)
continue
# Check the bottom wall
if (rand_wall[0] != height-1):
if (maze[rand_wall[0]+1][rand_wall[1]] == 'u' and maze[rand_wall[0]-1][rand_wall[1]] == 'c'):
s_cells = surroundingCells(rand_wall)
if (s_cells < 2):
# Denote the new path
maze[rand_wall[0]][rand_wall[1]] = 'c'
# Mark the new walls
if (rand_wall[0] != height-1):
if (maze[rand_wall[0]+1][rand_wall[1]] != 'c'):
maze[rand_wall[0]+1][rand_wall[1]] = 'w'
if ([rand_wall[0]+1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]+1, rand_wall[1]])
if (rand_wall[1] != 0):
if (maze[rand_wall[0]][rand_wall[1]-1] != 'c'):
maze[rand_wall[0]][rand_wall[1]-1] = 'w'
if ([rand_wall[0], rand_wall[1]-1] not in walls):
walls.append([rand_wall[0], rand_wall[1]-1])
if (rand_wall[1] != width-1):
if (maze[rand_wall[0]][rand_wall[1]+1] != 'c'):
maze[rand_wall[0]][rand_wall[1]+1] = 'w'
if ([rand_wall[0], rand_wall[1]+1] not in walls):
walls.append([rand_wall[0], rand_wall[1]+1])
# Delete wall
for wall in walls:
if (wall[0] == rand_wall[0] and wall[1] == rand_wall[1]):
walls.remove(wall)
continue
# Check the right wall
if (rand_wall[1] != width-1):
if (maze[rand_wall[0]][rand_wall[1]+1] == 'u' and maze[rand_wall[0]][rand_wall[1]-1] == 'c'):
s_cells = surroundingCells(rand_wall)
if (s_cells < 2):
# Denote the new path
maze[rand_wall[0]][rand_wall[1]] = 'c'
# Mark the new walls
if (rand_wall[1] != width-1):
if (maze[rand_wall[0]][rand_wall[1]+1] != 'c'):
maze[rand_wall[0]][rand_wall[1]+1] = 'w'
if ([rand_wall[0], rand_wall[1]+1] not in walls):
walls.append([rand_wall[0], rand_wall[1]+1])
if (rand_wall[0] != height-1):
if (maze[rand_wall[0]+1][rand_wall[1]] != 'c'):
maze[rand_wall[0]+1][rand_wall[1]] = 'w'
if ([rand_wall[0]+1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]+1, rand_wall[1]])
if (rand_wall[0] != 0):
if (maze[rand_wall[0]-1][rand_wall[1]] != 'c'):
maze[rand_wall[0]-1][rand_wall[1]] = 'w'
if ([rand_wall[0]-1, rand_wall[1]] not in walls):
walls.append([rand_wall[0]-1, rand_wall[1]])
# Delete wall
for wall in walls:
if (wall[0] == rand_wall[0] and wall[1] == rand_wall[1]):
walls.remove(wall)
continue
# Delete the wall from the list anyway
for wall in walls:
if (wall[0] == rand_wall[0] and wall[1] == rand_wall[1]):
walls.remove(wall)
# Mark the remaining unvisited cells as walls
for i in range(0, height):
for j in range(0, width):
if (maze[i][j] == 'u'):
maze[i][j] = 'w'
# Set entrance and exit
for i in range(0, width):
if (maze[1][i] == 'c'):
maze[0][i] = 'c'
break
for i in range(width-1, 0, -1):
if (maze[height-2][i] == 'c'):
maze[height-1][i] = 'c'
break
# Print final maze
printMaze(maze)
Recipe Hax
Hello Hacker Gentlemen.
Below are the 3 pieces of code we have at the moment. Your task is to edit the allrecipes.py code to make it more useful. At current, it creates an enormous list of completely unsorted recipes, and is functionally equivalent to throwing a box with thousands of recipe cards into a pile on the floor. You are now going to add some sorting to this to make it more useful. In total, your changes will probably be no more than 2-3 lines of code in allrecipes.py. Use regular expressions to, for example, create a separate text file for recipes that contain the word “pie” in the title. That is just one possibility, the sorting criteria is entirely up to you! If you would like to review/finish the lessons on the regex website, click here.
import re
#re stands for regular expressions
sentence = "The rain in Spain ComPLaiN, 8ain ain't 5ai9t ai"
# 01234567891111111
# 0123456
x = re.search("ai", sentence)
print(x.span())
# . is the metacharacter for any character (except for newline)
#[a-z] represents any lower case alpha character
#[A-Z] represents any upper case alpha character
#[0-9] represents any numeric character
#\w represents "word" characters, a-z, A-Z, 0-9, _ underscore
#\W represents anything that is NOT a "word" character
#\s string contains a whitespace character (space, tab, newline, return, feed)
#\S anything that is not a whitespace character
#* represents any number of the thing it follows
x = re.findall('[\w]*ai[\w]*',sentence)
print(x)
import requests, time, re
from recipe_scrapers import scrape_me
f = open("last_recipe_checked.txt",'rt')
content = f.readlines()
start = int(content[-1])
f.close()
currentrecipe = start
def main():
validrecipes = []
for i in range(start,9999999):
f = open("last_recipe_checked.txt",'w')########
f.write(str(i)+'\n')########
f.close() ########
url = 'https://cooking.nytimes.com/recipes/' + str(i)
time.sleep(0.25)
if requests.get(url).status_code == 200:
currentrecipe = i
recipe = scrape_me(url,wild_mode = True)
print(recipe.title(),i)
f = open("nytimesrecipes.txt","at")
f.write(recipe.title() + " " + url + '\n')
f.close()
validrecipes += [i]
if (__name__ == "__main__"):
main()
import requests, time
import requests, time
import shutil
from recipe_scrapers import scrape_me
url = 'https://cooking.nytimes.com/recipes/103'
recipe = scrape_me(url,wild_mode = True)
image_url = recipe.image()
file_name = recipe.title() + ' image.jpg'
res = requests.get(image_url, stream = True)
if res.status_code == 200:
with open(file_name,'wb') as f:
shutil.copyfileobj(res.raw, f)
print('Image sucessfully Downloaded: ',file_name)
else:
print('Image Couldn\'t be retrieved')
##################################################
from fpdf import FPDF
pdf = FPDF(orientation='P', unit = 'in', format = 'letter')
pdf.add_page()
pdf.set_xy(0.0,0.0)
pdf.set_font('Arial','B',16)
pdf.set_text_color(0,0,0)
pdf.cell(w=8.5,h=1.0, align = 'C', txt = recipe.title(), border = 0)
pdf.image(file_name, x = 2.75, y = 1, w = 3, h = 3, type = 'jpg', link = '')
pdf.set_font('Arial','',12)
pdf.set_text_color(0,0,0)
x = 4
for ingredient in recipe.ingredients():
pdf.cell(w=3.5,h=.25, align = 'L', txt = ingredient, border = 0)
x += 0.25
pdf.set_xy(1.0,x)
x+=1
pdf.set_xy(1.0,x)
pdf.multi_cell(w=7,h=0.25, align = 'L', txt = recipe.instructions(), border = 0)
pdf.output(file_name+'.pdf','F')
Training a Perceptron
import time
#runs scored per game
rsg = [4.26,4.75,4.19,4.52,4.28,4.36,4.41,4.39,4.54,3.24,4.49,3.82,3.92,5.19,3.99,4.67,4.56,4.66,
5.34,3.44,4.63,3.57,4.37,4.06,4.62,4.61,4.13,4.55,4.86,3.85]
#runs allowed per game
rag = [4.6,3.98,4.25,4.74,4.94,4.58,5.33,4.26,5.31,4.4,3.37,5.06,4.28,3.28,4.27,4.23,4.29,3.74,3.29,
4.5,4.12,5.04,4.07,3.85,4.36,4,3.93,4.47,4.29,5.45]
#is you winner or loser?
#I have included .500 teams as winner (you're welcome Chicago White Sox)
#1 means your team is losing (should be above the line), 0 means your team is winning (below the line)
w = [1,0,0,1,1,0,1,0,1,1,0,1,1,0,1,0,0,0,0,1,0,1,0,0,1,0,0,1,0,1]
teams = ['Arizona Diamondbacks','Atlanta Braves','Baltimore Orioles','Boston Red Sox','Chicago Cubs',
'Chicago White Sox','Cincinnati Reds','Cleveland Guardians','Colorado Rockies','Detroit Tigers',
'Houston Astros','Kansas City Royals','Los Angeles Angels','Los Angeles Dodgers','Miami Marlins',
'Milwaukee Brewers','Minnesota Twins','New York Mets','New York Yankees','Oakland Athletics',
'Philadelphia Phillies','Pittsburgh Pirates','San Diego Padres','Seattle Mariners',
'San Francisco Giants','St. Louis Cardinals','Tampa Bay Rays','Texas Rangers','Toronto Blue Jays',
'Washington Nationals']
#winner runs scored
winner_rsg = []
#loser runs scored
loser_rsg = []
#winner runs allowed
winner_rag = []
#loser runs allowed
loser_rag = []
#now separate all the data into 2 sets: winners and losers
for i in range(len(rsg)):
if w[i] > 0:
loser_rsg += [rsg[i]]
loser_rag += [rag[i]]
else:
winner_rsg += [rsg[i]]
winner_rag += [rag[i]]
import matplotlib.pyplot as plt
speed = 0.5 #how many seconds in between graphs
#draw a scatter plot of actual winners and losers as of 7/31/2022
def draw_scatter():
for i, label in enumerate(teams):
plt.annotate(label, (rsg[i]+0.02, rag[i]+0.02))
plt.title("Separating Winning Teams By Runs Allowed and Scored")
plt.xlabel("Runs Scored/Game")
plt.ylabel("Runs Allowed/Game")
plt.scatter(winner_rsg, winner_rag)
plt.scatter(loser_rsg, loser_rag)
plt.legend(['Winning Teams','Losing Teams'])
plt.ion()
draw_scatter()
x = list(range(30,55,1))
x = [data/10 for data in x]
#starting coefficients
#coefficients = [w0, w1, w2]
#you can basically start these coefficients with any random numbers because you haven't even looked a team yet
coeff = [0, 1, 0.5]
#now we will graph the first hypothesized line based on just a random guess
y = [(coeff[1]*data -1*coeff[0])/coeff[2] for data in x]
plt.plot(x,y) #use a line graph
plt.draw() #draw the graph
plt.pause(speed) #wait 1 second
plt.clf() #clear the graph
n = 0.2 #this number determins how much the graph changes when you find a new point to classify
#now we are going to go through the real data points for all 30 of the teams
for i in range(len(rsg)):
pointvalue = coeff[1]*rag[i] + coeff[2]*rsg[i] + coeff[0] * 1
#these are the 2 options for properly classified points, so d = 1
if (w[i] == 1 and pointvalue > 1) or (w[i] == 0 and pointvalue < 1):
d = 1
#these are the 2 options for misclassified points, so d = -1
if (w[i] == 0 and pointvalue > 1) or (w[i] == 1 and pointvalue < 1):
d = -1
#if d=-1, we have found a misclassified point, so we will update the list of coefficients for the new point
if d == -1:
coeff[0] = coeff[0] + n * d * 1
coeff[1] = coeff[1] + n * d * rag[i]
coeff[2] = coeff[2] + n * d * rsg[i]
#now replot the dividing line
y = [(coeff[1]*data -1*coeff[0])/coeff[2] for data in x]
draw_scatter()
plt.plot(x,y)
plt.draw()
plt.pause(speed)
#only clear if you aren't on the final data point
if i != len(rsg)-1:
plt.clf()
print(coeff)
How Do Stepper Motors Work
Max6675 Thermocouple Arduino Code
#include "Max6675.h"
Max6675 ts(8, 9, 10);
// Max6675 module: SO on pin #8, SS on pin #9, CSK on pin #10 of Arduino UNO
void setup()
{
ts.setOffset(0);
// set offset for temperature measurement.
Serial.begin(9600);
}
void loop()
{
Serial.print(ts.getCelsius(), 2);
Serial.print(" C / ");
Serial.print(ts.getFahrenheit(), 2);
Serial.print(" F / ");
Serial.print(ts.getKelvin(), 2);
Serial.print(" Kn");
Serial.println();
delay(2000);
}
Minmax Tic Tac Toe
#!/usr/bin/env python3
from math import inf as infinity
from random import choice
import platform
import time
from os import system
HUMAN = -1
COMP = +1
board = [
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
]
def evaluate(state):
"""
Function to heuristic evaluation of state.
:param state: the state of the current board
:return: +1 if the computer wins; -1 if the human wins; 0 draw
"""
if wins(state, COMP):
score = +1
elif wins(state, HUMAN):
score = -1
else:
score = 0
return score
def wins(state, player):
"""
This function tests if a specific player wins. Possibilities:
* Three rows [X X X] or [O O O]
* Three cols [X X X] or [O O O]
* Two diagonals [X X X] or [O O O]
:param state: the state of the current board
:param player: a human or a computer
:return: True if the player wins
"""
win_state = [
[state[0][0], state[0][1], state[0][2]],
[state[1][0], state[1][1], state[1][2]],
[state[2][0], state[2][1], state[2][2]],
[state[0][0], state[1][0], state[2][0]],
[state[0][1], state[1][1], state[2][1]],
[state[0][2], state[1][2], state[2][2]],
[state[0][0], state[1][1], state[2][2]],
[state[2][0], state[1][1], state[0][2]],
]
if [player, player, player] in win_state:
return True
else:
return False
def game_over(state):
"""
This function test if the human or computer wins
:param state: the state of the current board
:return: True if the human or computer wins
"""
return wins(state, HUMAN) or wins(state, COMP)
def empty_cells(state):
"""
Each empty cell will be added into cells' list
:param state: the state of the current board
:return: a list of empty cells
"""
cells = []
for x, row in enumerate(state):
for y, cell in enumerate(row):
if cell == 0:
cells.append([x, y])
return cells
def valid_move(x, y):
"""
A move is valid if the chosen cell is empty
:param x: X coordinate
:param y: Y coordinate
:return: True if the board[x][y] is empty
"""
if [x, y] in empty_cells(board):
return True
else:
return False
def set_move(x, y, player):
"""
Set the move on board, if the coordinates are valid
:param x: X coordinate
:param y: Y coordinate
:param player: the current player
"""
if valid_move(x, y):
board[x][y] = player
return True
else:
return False
def minimax(state, depth, player):
"""
AI function that choice the best move
:param state: current state of the board
:param depth: node index in the tree (0 <= depth <= 9),
but never nine in this case (see iaturn() function)
:param player: an human or a computer
:return: a list with [the best row, best col, best score]
"""
if player == COMP:
best = [-1, -1, -infinity]
else:
best = [-1, -1, +infinity]
if depth == 0 or game_over(state):
score = evaluate(state)
return [-1, -1, score]
for cell in empty_cells(state):
x, y = cell[0], cell[1]
state[x][y] = player
score = minimax(state, depth - 1, -player)
state[x][y] = 0
score[0], score[1] = x, y
if player == COMP:
if score[2] > best[2]:
best = score # max value
else:
if score[2] < best[2]:
best = score # min value
return best
def clean():
"""
Clears the console
"""
os_name = platform.system().lower()
if 'windows' in os_name:
system('cls')
else:
system('clear')
def render(state, c_choice, h_choice):
"""
Print the board on console
:param state: current state of the board
"""
chars = {
-1: h_choice,
+1: c_choice,
0: ' '
}
str_line = '---------------'
print('\n' + str_line)
for row in state:
for cell in row:
symbol = chars[cell]
print(f'| {symbol} |', end='')
print('\n' + str_line)
def ai_turn(c_choice, h_choice):
"""
It calls the minimax function if the depth < 9,
else it choices a random coordinate.
:param c_choice: computer's choice X or O
:param h_choice: human's choice X or O
:return:
"""
depth = len(empty_cells(board))
if depth == 0 or game_over(board):
return
clean()
print(f'Computer turn [{c_choice}]')
render(board, c_choice, h_choice)
if depth == 9:
x = choice([0, 1, 2])
y = choice([0, 1, 2])
else:
move = minimax(board, depth, COMP)
x, y = move[0], move[1]
set_move(x, y, COMP)
time.sleep(1)
def human_turn(c_choice, h_choice):
"""
The Human plays choosing a valid move.
:param c_choice: computer's choice X or O
:param h_choice: human's choice X or O
:return:
"""
depth = len(empty_cells(board))
if depth == 0 or game_over(board):
return
# Dictionary of valid moves
move = -1
moves = {
1: [0, 0], 2: [0, 1], 3: [0, 2],
4: [1, 0], 5: [1, 1], 6: [1, 2],
7: [2, 0], 8: [2, 1], 9: [2, 2],
}
clean()
print(f'Human turn [{h_choice}]')
render(board, c_choice, h_choice)
while move < 1 or move > 9:
try:
move = int(input('Use numpad (1..9): '))
coord = moves[move]
can_move = set_move(coord[0], coord[1], HUMAN)
if not can_move:
print('Bad move')
move = -1
except (EOFError, KeyboardInterrupt):
print('Bye')
exit()
except (KeyError, ValueError):
print('Bad choice')
def main():
"""
Main function that calls all functions
"""
clean()
h_choice = '' # X or O
c_choice = '' # X or O
first = '' # if human is the first
# Human chooses X or O to play
while h_choice != 'O' and h_choice != 'X':
try:
print('')
h_choice = input('Choose X or O\nChosen: ').upper()
except (EOFError, KeyboardInterrupt):
print('Bye')
exit()
except (KeyError, ValueError):
print('Bad choice')
# Setting computer's choice
if h_choice == 'X':
c_choice = 'O'
else:
c_choice = 'X'
# Human may starts first
clean()
while first != 'Y' and first != 'N':
try:
first = input('First to start?[y/n]: ').upper()
except (EOFError, KeyboardInterrupt):
print('Bye')
exit()
except (KeyError, ValueError):
print('Bad choice')
# Main loop of this game
while len(empty_cells(board)) > 0 and not game_over(board):
if first == 'N':
ai_turn(c_choice, h_choice)
first = ''
human_turn(c_choice, h_choice)
ai_turn(c_choice, h_choice)
# Game over message
if wins(board, HUMAN):
clean()
print(f'Human turn [{h_choice}]')
render(board, c_choice, h_choice)
print('YOU WIN!')
elif wins(board, COMP):
clean()
print(f'Computer turn [{c_choice}]')
render(board, c_choice, h_choice)
print('YOU LOSE!')
else:
clean()
render(board, c_choice, h_choice)
print('DRAW!')
exit()
main()
Naive Learning
import itertools
import time
import numpy as np
import cv2
from moviepy.editor import VideoClip
WORLD_HEIGHT = 4
WORLD_WIDTH = 4
WALL_FRAC = .2
NUM_WINS = 5
NUM_LOSE = 10
class GridWorld:
def __init__(self, world_height=3, world_width=4, discount_factor=.5, default_reward=-.5, wall_penalty=-.6,
win_reward=5., lose_reward=-10., viz=True, patch_side=120, grid_thickness=2, arrow_thickness=3,
wall_locs=[[1, 1], [1, 2]], win_locs=[[0, 3]], lose_locs=[[1, 3]], start_loc=[0, 0],
reset_prob=.2):
self.world = np.ones([world_height, world_width]) * default_reward
self.reset_prob = reset_prob
self.world_height = world_height
self.world_width = world_width
self.wall_penalty = wall_penalty
self.win_reward = win_reward
self.lose_reward = lose_reward
self.default_reward = default_reward
self.discount_factor = discount_factor
self.patch_side = patch_side
self.grid_thickness = grid_thickness
self.arrow_thickness = arrow_thickness
self.wall_locs = np.array(wall_locs)
self.win_locs = np.array(win_locs)
self.lose_locs = np.array(lose_locs)
self.at_terminal_state = False
self.auto_reset = True
self.random_respawn = True
self.step = 0
self.viz_canvas = None
self.viz = viz
self.path_color = (128, 128, 128)
self.wall_color = (0, 255, 0)
self.win_color = (0, 0, 255)
self.lose_color = (255, 0, 0)
self.world[self.wall_locs[:, 0], self.wall_locs[:, 1]] = self.wall_penalty
self.world[self.lose_locs[:, 0], self.lose_locs[:, 1]] = self.lose_reward
self.world[self.win_locs[:, 0], self.win_locs[:, 1]] = self.win_reward
spawn_condn = lambda loc: self.world[loc[0], loc[1]] == self.default_reward
self.spawn_locs = np.array([loc for loc in itertools.product(np.arange(self.world_height),
np.arange(self.world_width))
if spawn_condn(loc)])
self.start_state = np.array(start_loc)
self.bot_rc = None
self.reset()
self.actions = [self.up, self.left, self.right, self.down, self.noop]
self.action_labels = ['UP', 'LEFT', 'RIGHT', 'DOWN', 'NOOP']
self.q_values = np.ones([self.world.shape[0], self.world.shape[1], len(self.actions)]) * 1. / len(self.actions)
if self.viz:
self.init_grid_canvas()
self.video_out_fpath = 'shm_dqn_gridsolver-' + str(time.time()) + '.mp4'
self.clip = VideoClip(self.make_frame, duration=15)
def make_frame(self, t):
self.action()
frame = self.highlight_loc(self.viz_canvas, self.bot_rc[0], self.bot_rc[1])
return frame
def check_terminal_state(self):
if self.world[self.bot_rc[0], self.bot_rc[1]] == self.lose_reward \
or self.world[self.bot_rc[0], self.bot_rc[1]] == self.win_reward:
self.at_terminal_state = True
# print('------++++---- TERMINAL STATE ------++++----')
# if self.world[self.bot_rc[0], self.bot_rc[1]] == self.win_reward:
# print('GAME WON! :D')
# elif self.world[self.bot_rc[0], self.bot_rc[1]] == self.lose_reward:
# print('GAME LOST! :(')
if self.auto_reset:
self.reset()
def reset(self):
# print('Resetting')
if not self.random_respawn:
self.bot_rc = self.start_state.copy()
else:
self.bot_rc = self.spawn_locs[np.random.choice(np.arange(len(self.spawn_locs)))].copy()
self.at_terminal_state = False
def up(self):
action_idx = 0
# print(self.action_labels[action_idx])
new_r = self.bot_rc[0] - 1
if new_r < 0 or self.world[new_r, self.bot_rc[1]] == self.wall_penalty:
return self.wall_penalty, action_idx
self.bot_rc[0] = new_r
reward = self.world[self.bot_rc[0], self.bot_rc[1]]
self.check_terminal_state()
return reward, action_idx
def left(self):
action_idx = 1
# print(self.action_labels[action_idx])
new_c = self.bot_rc[1] - 1
if new_c < 0 or self.world[self.bot_rc[0], new_c] == self.wall_penalty:
return self.wall_penalty, action_idx
self.bot_rc[1] = new_c
reward = self.world[self.bot_rc[0], self.bot_rc[1]]
self.check_terminal_state()
return reward, action_idx
def right(self):
action_idx = 2
# print(self.action_labels[action_idx])
new_c = self.bot_rc[1] + 1
if new_c >= self.world.shape[1] or self.world[self.bot_rc[0], new_c] == self.wall_penalty:
return self.wall_penalty, action_idx
self.bot_rc[1] = new_c
reward = self.world[self.bot_rc[0], self.bot_rc[1]]
self.check_terminal_state()
return reward, action_idx
def down(self):
action_idx = 3
# print(self.action_labels[action_idx])
new_r = self.bot_rc[0] + 1
if new_r >= self.world.shape[0] or self.world[new_r, self.bot_rc[1]] == self.wall_penalty:
return self.wall_penalty, action_idx
self.bot_rc[0] = new_r
reward = self.world[self.bot_rc[0], self.bot_rc[1]]
self.check_terminal_state()
return reward, action_idx
def noop(self):
action_idx = 4
# print(self.action_labels[action_idx])
reward = self.world[self.bot_rc[0], self.bot_rc[1]]
self.check_terminal_state()
return reward, action_idx
def qvals2probs(self, q_vals, epsilon=1e-4):
action_probs = q_vals - q_vals.min() + epsilon
action_probs = action_probs / action_probs.sum()
return action_probs
def action(self):
# print('================ ACTION =================')
if self.at_terminal_state:
print('At terminal state, please call reset()')
exit()
# print('Start position:', self.bot_rc)
start_bot_rc = self.bot_rc[0], self.bot_rc[1]
q_vals = self.q_values[self.bot_rc[0], self.bot_rc[1]]
action_probs = self.qvals2probs(q_vals)
reward, action_idx = np.random.choice(self.actions, p=action_probs)()
# print('End position:', self.bot_rc)
# print('Reward:', reward)
alpha = np.exp(-self.step / 10e9)
self.step += 1
qv = (1 - alpha) * q_vals[action_idx] + alpha * (reward + self.discount_factor
* self.q_values[self.bot_rc[0], self.bot_rc[1]].max())
self.q_values[start_bot_rc[0], start_bot_rc[1], action_idx] = qv
if self.viz:
self.update_viz(start_bot_rc[0], start_bot_rc[1])
if np.random.rand() < self.reset_prob:
# print('-----> Randomly resetting to a random spawn point with probability', self.reset_prob)
self.reset()
def highlight_loc(self, viz_in, i, j):
starty = i * (self.patch_side + self.grid_thickness)
endy = starty + self.patch_side
startx = j * (self.patch_side + self.grid_thickness)
endx = startx + self.patch_side
viz = viz_in.copy()
cv2.rectangle(viz, (startx, starty), (endx, endy), (255, 255, 255), thickness=self.grid_thickness)
return viz
def update_viz(self, i, j):
starty = i * (self.patch_side + self.grid_thickness)
endy = starty + self.patch_side
startx = j * (self.patch_side + self.grid_thickness)
endx = startx + self.patch_side
patch = np.zeros([self.patch_side, self.patch_side, 3]).astype(np.uint8)
if self.world[i, j] == self.default_reward:
patch[:, :, :] = self.path_color
elif self.world[i, j] == self.wall_penalty:
patch[:, :, :] = self.wall_color
elif self.world[i, j] == self.win_reward:
patch[:, :, :] = self.win_color
elif self.world[i, j] == self.lose_reward:
patch[:, :, :] = self.lose_color
if self.world[i, j] == self.default_reward:
action_probs = self.qvals2probs(self.q_values[i, j])
x_component = action_probs[2] - action_probs[1]
y_component = action_probs[0] - action_probs[3]
magnitude = 1. - action_probs[-1]
s = self.patch_side // 2
x_patch = int(s * x_component)
y_patch = int(s * y_component)
arrow_canvas = np.zeros_like(patch)
vx = s + x_patch
vy = s - y_patch
cv2.arrowedLine(arrow_canvas, (s, s), (vx, vy), (255, 255, 255), thickness=self.arrow_thickness,
tipLength=0.5)
gridbox = (magnitude * arrow_canvas + (1 - magnitude) * patch).astype(np.uint8)
self.viz_canvas[starty:endy, startx:endx] = gridbox
else:
self.viz_canvas[starty:endy, startx:endx] = patch
def init_grid_canvas(self):
org_h, org_w = self.world_height, self.world_width
viz_w = (self.patch_side * org_w) + (self.grid_thickness * (org_w - 1))
viz_h = (self.patch_side * org_h) + (self.grid_thickness * (org_h - 1))
self.viz_canvas = np.zeros([viz_h, viz_w, 3]).astype(np.uint8)
for i in range(org_h):
for j in range(org_w):
self.update_viz(i, j)
def solve(self):
if not self.viz:
while True:
self.action()
else:
self.clip.write_videofile(self.video_out_fpath, fps=460)
def gen_world_config(h, w, wall_frac=.5, num_wins=2, num_lose=3):
n = h * w
num_wall_blocks = int(wall_frac * n)
wall_locs = (np.random.rand(num_wall_blocks, 2) * [h, w]).astype(np.int)
win_locs = (np.random.rand(num_wins, 2) * [h, w]).astype(np.int)
lose_locs = (np.random.rand(num_lose, 2) * [h, w]).astype(np.int)
return wall_locs, win_locs, lose_locs
if __name__ == '__main__':
wall_locs, win_locs, lose_locs = gen_world_config(WORLD_HEIGHT, WORLD_WIDTH, WALL_FRAC, NUM_WINS, NUM_LOSE)
g = GridWorld(world_height=WORLD_HEIGHT, world_width=WORLD_WIDTH,
wall_locs=wall_locs, win_locs=win_locs, lose_locs=lose_locs, viz=True)
g.solve()
k = 0
Javascript Tetris – A Simple Implementation
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<style>
canvas {
position: absolute;
top: 45%;
left: 50%;
width: 640px;
height: 640px;
margin: -320px 0 0 -320px;
}
</style>
</head>
<body>
<canvas></canvas>
<script>
'use strict';
var canvas = document.querySelector('canvas');
canvas.width = 640;
canvas.height = 640;
var g = canvas.getContext('2d');
var right = { x: 1, y: 0 };
var down = { x: 0, y: 1 };
var left = { x: -1, y: 0 };
var EMPTY = -1;
var BORDER = -2;
var fallingShape;
var nextShape;
var dim = 640;
var nRows = 18;
var nCols = 12;
var blockSize = 30;
var topMargin = 50;
var leftMargin = 20;
var scoreX = 400;
var scoreY = 330;
var titleX = 130;
var titleY = 160;
var clickX = 120;
var clickY = 400;
var previewCenterX = 467;
var previewCenterY = 97;
var mainFont = 'bold 48px monospace';
var smallFont = 'bold 18px monospace';
var colors = ['green', 'red', 'blue', 'purple', 'orange', 'blueviolet', 'magenta'];
var gridRect = { x: 46, y: 47, w: 308, h: 517 };
var previewRect = { x: 387, y: 47, w: 200, h: 200 };
var titleRect = { x: 100, y: 95, w: 252, h: 100 };
var clickRect = { x: 50, y: 375, w: 252, h: 40 };
var outerRect = { x: 5, y: 5, w: 630, h: 630 };
var squareBorder = 'white';
var titlebgColor = 'white';
var textColor = 'black';
var bgColor = '#DDEEFF';
var gridColor = '#BECFEA';
var gridBorderColor = '#7788AA';
var largeStroke = 5;
var smallStroke = 2;
// position of falling shape
var fallingShapeRow;
var fallingShapeCol;
var keyDown = false;
var fastDown = false;
var grid = [];
var scoreboard = new Scoreboard();
addEventListener('keydown', function (event) {
if (!keyDown) {
keyDown = true;
if (scoreboard.isGameOver())
return;
switch (event.key) {
case 'w':
case 'ArrowUp':
if (canRotate(fallingShape))
rotate(fallingShape);
break;
case 'a':
case 'ArrowLeft':
if (canMove(fallingShape, left))
move(left);
break;
case 'd':
case 'ArrowRight':
if (canMove(fallingShape, right))
move(right);
break;
case 's':
case 'ArrowDown':
if (!fastDown) {
fastDown = true;
while (canMove(fallingShape, down)) {
move(down);
draw();
}
shapeHasLanded();
}
}
draw();
}
});
addEventListener('click', function () {
startNewGame();
});
addEventListener('keyup', function () {
keyDown = false;
fastDown = false;
});
function canRotate(s) {
if (s === Shapes.Square)
return false;
var pos = new Array(4);
for (var i = 0; i < pos.length; i++) {
pos[i] = s.pos[i].slice();
}
pos.forEach(function (row) {
var tmp = row[0];
row[0] = row[1];
row[1] = -tmp;
});
return pos.every(function (p) {
var newCol = fallingShapeCol + p[0];
var newRow = fallingShapeRow + p[1];
return grid[newRow][newCol] === EMPTY;
});
}
function rotate(s) {
if (s === Shapes.Square)
return;
s.pos.forEach(function (row) {
var tmp = row[0];
row[0] = row[1];
row[1] = -tmp;
});
}
function move(dir) {
fallingShapeRow += dir.y;
fallingShapeCol += dir.x;
}
function canMove(s, dir) {
return s.pos.every(function (p) {
var newCol = fallingShapeCol + dir.x + p[0];
var newRow = fallingShapeRow + dir.y + p[1];
return grid[newRow][newCol] === EMPTY;
});
}
function shapeHasLanded() {
addShape(fallingShape);
if (fallingShapeRow < 2) {
scoreboard.setGameOver();
scoreboard.setTopscore();
} else {
scoreboard.addLines(removeLines());
}
selectShape();
}
function removeLines() {
var count = 0;
for (var r = 0; r < nRows - 1; r++) {
for (var c = 1; c < nCols - 1; c++) {
if (grid[r][c] === EMPTY)
break;
if (c === nCols - 2) {
count++;
removeLine(r);
}
}
}
return count;
}
function removeLine(line) {
for (var c = 0; c < nCols; c++)
grid[line][c] = EMPTY;
for (var c = 0; c < nCols; c++) {
for (var r = line; r > 0; r--)
grid[r][c] = grid[r - 1][c];
}
}
function addShape(s) {
s.pos.forEach(function (p) {
grid[fallingShapeRow + p[1]][fallingShapeCol + p[0]] = s.ordinal;
});
}
function Shape(shape, o) {
this.shape = shape;
this.pos = this.reset();
this.ordinal = o;
}
var Shapes = {
ZShape: [[0, -1], [0, 0], [-1, 0], [-1, 1]],
SShape: [[0, -1], [0, 0], [1, 0], [1, 1]],
IShape: [[0, -1], [0, 0], [0, 1], [0, 2]],
TShape: [[-1, 0], [0, 0], [1, 0], [0, 1]],
Square: [[0, 0], [1, 0], [0, 1], [1, 1]],
LShape: [[-1, -1], [0, -1], [0, 0], [0, 1]],
JShape: [[1, -1], [0, -1], [0, 0], [0, 1]]
};
function getRandomShape() {
var keys = Object.keys(Shapes);
var ord = Math.floor(Math.random() * keys.length);
var shape = Shapes[keys[ord]];
return new Shape(shape, ord);
}
Shape.prototype.reset = function () {
this.pos = new Array(4);
for (var i = 0; i < this.pos.length; i++) {
this.pos[i] = this.shape[i].slice();
}
return this.pos;
}
function selectShape() {
fallingShapeRow = 1;
fallingShapeCol = 5;
fallingShape = nextShape;
nextShape = getRandomShape();
if (fallingShape != null) {
fallingShape.reset();
}
}
function Scoreboard() {
this.MAXLEVEL = 9;
var level = 0;
var lines = 0;
var score = 0;
var topscore = 0;
var gameOver = true;
this.reset = function () {
this.setTopscore();
level = lines = score = 0;
gameOver = false;
}
this.setGameOver = function () {
gameOver = true;
}
this.isGameOver = function () {
return gameOver;
}
this.setTopscore = function () {
if (score > topscore) {
topscore = score;
}
}
this.getTopscore = function () {
return topscore;
}
this.getSpeed = function () {
switch (level) {
case 0: return 700;
case 1: return 600;
case 2: return 500;
case 3: return 400;
case 4: return 350;
case 5: return 300;
case 6: return 250;
case 7: return 200;
case 8: return 150;
case 9: return 100;
default: return 100;
}
}
this.addScore = function (sc) {
score += sc;
}
this.addLines = function (line) {
switch (line) {
case 1:
this.addScore(10);
break;
case 2:
this.addScore(20);
break;
case 3:
this.addScore(30);
break;
case 4:
this.addScore(40);
break;
default:
return;
}
lines += line;
if (lines > 10) {
this.addLevel();
}
}
this.addLevel = function () {
lines %= 10;
if (level < this.MAXLEVEL) {
level++;
}
}
this.getLevel = function () {
return level;
}
this.getLines = function () {
return lines;
}
this.getScore = function () {
return score;
}
}
function draw() {
g.clearRect(0, 0, canvas.width, canvas.height);
drawUI();
if (scoreboard.isGameOver()) {
drawStartScreen();
} else {
drawFallingShape();
}
}
function drawStartScreen() {
g.font = mainFont;
fillRect(titleRect, titlebgColor);
fillRect(clickRect, titlebgColor);
g.fillStyle = textColor;
g.fillText('Tetris', titleX, titleY);
g.font = smallFont;
g.fillText('click to start', clickX, clickY);
}
function fillRect(r, color) {
g.fillStyle = color;
g.fillRect(r.x, r.y, r.w, r.h);
}
function drawRect(r, color) {
g.strokeStyle = color;
g.strokeRect(r.x, r.y, r.w, r.h);
}
function drawSquare(colorIndex, r, c) {
var bs = blockSize;
g.fillStyle = colors[colorIndex];
g.fillRect(leftMargin + c * bs, topMargin + r * bs, bs, bs);
g.lineWidth = smallStroke;
g.strokeStyle = squareBorder;
g.strokeRect(leftMargin + c * bs, topMargin + r * bs, bs, bs);
}
function drawUI() {
// background
fillRect(outerRect, bgColor);
fillRect(gridRect, gridColor);
// the blocks dropped in the grid
for (var r = 0; r < nRows; r++) {
for (var c = 0; c < nCols; c++) {
var idx = grid[r][c];
if (idx > EMPTY)
drawSquare(idx, r, c);
}
}
// the borders of grid and preview panel
g.lineWidth = largeStroke;
drawRect(gridRect, gridBorderColor);
drawRect(previewRect, gridBorderColor);
drawRect(outerRect, gridBorderColor);
// scoreboard
g.fillStyle = textColor;
g.font = smallFont;
g.fillText('hiscore ' + scoreboard.getTopscore(), scoreX, scoreY);
g.fillText('level ' + scoreboard.getLevel(), scoreX, scoreY + 30);
g.fillText('lines ' + scoreboard.getLines(), scoreX, scoreY + 60);
g.fillText('score ' + scoreboard.getScore(), scoreX, scoreY + 90);
// preview
var minX = 5, minY = 5, maxX = 0, maxY = 0;
nextShape.pos.forEach(function (p) {
minX = Math.min(minX, p[0]);
minY = Math.min(minY, p[1]);
maxX = Math.max(maxX, p[0]);
maxY = Math.max(maxY, p[1]);
});
var cx = previewCenterX - ((minX + maxX + 1) / 2.0 * blockSize);
var cy = previewCenterY - ((minY + maxY + 1) / 2.0 * blockSize);
g.translate(cx, cy);
nextShape.shape.forEach(function (p) {
drawSquare(nextShape.ordinal, p[1], p[0]);
});
g.translate(-cx, -cy);
}
function drawFallingShape() {
var idx = fallingShape.ordinal;
fallingShape.pos.forEach(function (p) {
drawSquare(idx, fallingShapeRow + p[1], fallingShapeCol + p[0]);
});
}
function animate(lastFrameTime) {
var requestId = requestAnimationFrame(function () {
animate(lastFrameTime);
});
var time = new Date().getTime();
var delay = scoreboard.getSpeed();
if (lastFrameTime + delay < time) {
if (!scoreboard.isGameOver()) {
if (canMove(fallingShape, down)) {
move(down);
} else {
shapeHasLanded();
}
draw();
lastFrameTime = time;
} else {
cancelAnimationFrame(requestId);
}
}
}
function startNewGame() {
initGrid();
selectShape();
scoreboard.reset();
animate(-1);
}
function initGrid() {
function fill(arr, value) {
for (var i = 0; i < arr.length; i++) {
arr[i] = value;
}
}
for (var r = 0; r < nRows; r++) {
grid[r] = new Array(nCols);
fill(grid[r], EMPTY);
for (var c = 0; c < nCols; c++) {
if (c === 0 || c === nCols - 1 || r === nRows - 1)
grid[r][c] = BORDER;
}
}
}
function init() {
initGrid();
selectShape();
draw();
}
init();
</script>
</body>
</html>
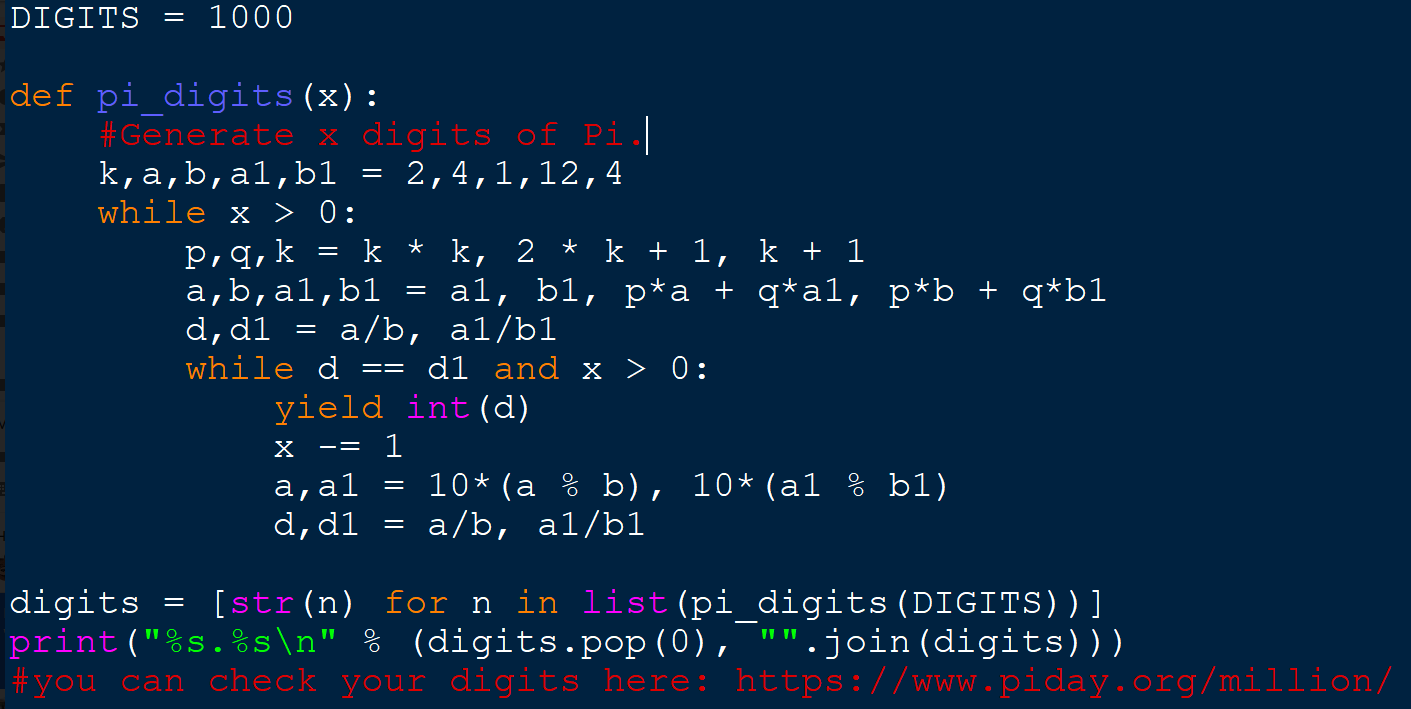
Calculating the nth Digit of Pi